Consensus
# Consensus
Processes propose values and they all have to agree on one of these values.
- Single Value Consensus
- Validity: decided values are those which are proposed
- Agreement: no 2 correct processes decide differently
- Termination: every correct process eventually decides
- Integrity: a process decides at most once
- Single Value Uniform Consensus
- Uniform Agreement: no 2 processes decide different values Consensus is not solvable in the asynchronous system model if any node is allowed to fail
- Unable to detect failure
- Cannot wait for the correct majority of processes
- Termination not satisfied: cannot decide
# Paxos Algorithm
An
Eventual Leader Election (weakest leader elector we can use) can be used to eventually elect 1 single proposer (providing termination).

- Proposers: attempt to impose their proposal to acceptors
- Acceptors: may accept values issued by proposers (cannot talk to each other)
- Learners: decide depending on what is accepted Contention problem: several processes might initially be proposers
# Abortable Consensus
Algorithm aborts if there is contention of multiple proposers.
# Version 1 (Centralised)
Proposer sends value to a central acceptor. Acceptor decides on the first value which it gets. Problem 1: if this acceptor fails, we will never know of the decision
# Version 2 (Decentralised)
Proposers talk to a set of acceptors, use a majority
quorum to choose a value and enable fault tolerance.
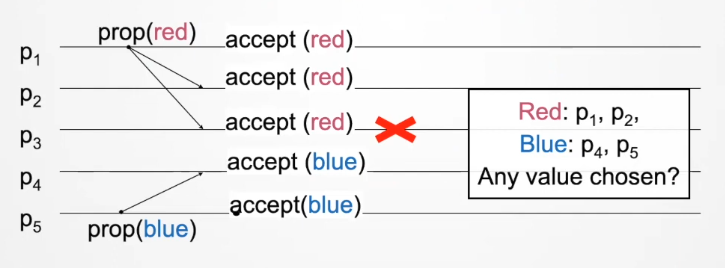
Problem 2: acceptor accepts the first proposal, if messages arrive out of order, possible to have no majority
# Version 3 (Enable restarts)
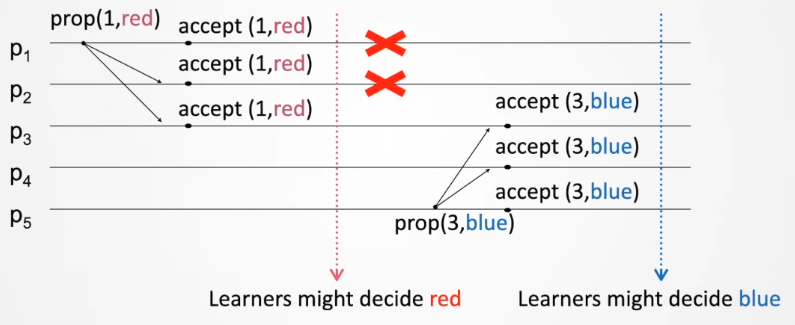
If no majority value, we need to restart until there is one. Since proposers can propose again, we need a way to differentiate between them.
- Use a ballot number: sequence number in the form $i, n+i, 2n+i$ for a process $i$ and $n$ processes
Problem 3: restarts lead to different majority accepted values across time, learners cannot make a single decision
# Version 4 (Prepare and Accept)
We need a way to ensure that every higher number proposal results in the same chosen value
- Satisfied by ensuring acceptors only accept this value
- Satisfied by ensuring proposers only propose this value
- Proposers need to learn this value from the highest sequence number of those accepted. Proposers need to ensure that this “highest value” does not change. Proposers query acceptors so that if a value is accepted, every higher proposal issued has the same value previously accepted
- Proposer $prepare(n)$:
- Gets a promise from acceptors not to accept a proposal with lower ballot number n
- Acceptor also responds with the value corresponding to the highest ballot number proposal
- Proposer $accept(n,v)$:
- Pick the value from the maximum proposal number returned. If none of the processes return a value, proposer can pick freely.
- Acceptor $accept(n,v)$ if not accepted any $prepare(m)$ such that $m>n$; else $reject$
- Proposer $decide(v)$ if majority acks; else $abort$

# Optimisations
- Reject
prepare(n)if acceptedprepare(m); m > n: Reject a lower prepare - Reject
accept(n,v)if answeredaccept(m,u); m > n: Reject a lower accept - Reject
prepare(n)if answeredaccept(m,u); m > n: Reject a lower accept - Ignore messages if majority obtained
# Multi Paxos
The motivation: replicated state machines need to agree on a sequence of commands to execute.
Approach: organise the algorithm into rounds. In each round, each server starts a new instance of Paxos. They propose (2 RTT), accept (2 RTT) and decide on 1 command, add that to the log and restart.
Initial states
- $ProCmds = \emptyset$: stores the list of commands proposed
- Log = <>: a log of decided commands
A process which wants to execute a command C triggers $rb-broadcast<C, Pid>$. On delivery, the command pair is added to
ProCmdsunless it is already in Log. Problem: the same command across multiple processes might be decided in different slots in time.
Problem: the same command across multiple processes might be decided in different slots in time.
# Sequence Consensus
Rather than agreeing on a single command and storing that in a Log, we can directly try to agree on the sequence of commands.
- Validity: if process p decides on a value, the value is a sequence of commands
- Uniform Agreement: if process p decides u and another decides v, then one is a prefix of the other
- Integrity: process can later decide another value, but the previous value is a strict prefix of the newly decided value
- Termination
After adopting a value with highest proposal number, the proposer is allowed to extend the sequence with the new command.
 Problem: in the prepare phase, processes send a lot of redundant state as the full log is transferred between the proposer and acceptor leading to high IO. No pipelining as well since each round must begin with the prepare phase.
Problem: in the prepare phase, processes send a lot of redundant state as the full log is transferred between the proposer and acceptor leading to high IO. No pipelining as well since each round must begin with the prepare phase.
# Log Synchronisation
Modify the prepare phase and shared states such that we can work on a single synchronised log $v_a$. To do this, let 1 process act as the sole leader (proposer) until it is aborted by an election of higher ballot number

# Prepare Phase
The leader sends Prepare:
- current round: $n$
- accepted round: $n_a$
- log length: $|v_a|$
- decided index $l_d$, where the decided sequence is $prefix(v_a,l_d)$
The followers reply with
Promise: - their accepted round
- the log entries which the leader is missing and the leader appends those to the log.
AcceptSyncis used to synchronise the new log. Promised followers and leader now have the same common log prefix
# Accept Phase
The leader sends Accept command with highest $n$ to all promised followers
The followers reply with Accepted
When majority accepted, Decide is sent.
Any late Promise is replied with an AcceptSync

# Partial Connectivity (enabling quorum connectedness)
Chained scenario:
 When one server loses connectivity to the leader, it will try to elect itself as a leader. Livelock situation as servers compete to become the leader. Can be solved if A becomes the leader but can’t because it is already connected to a leader.
Quorum Loss:
When one server loses connectivity to the leader, it will try to elect itself as a leader. Livelock situation as servers compete to become the leader. Can be solved if A becomes the leader but can’t because it is already connected to a leader.
Quorum Loss:
 When the leader loses quorum connectivity, deadlock situation as a majority cannot be obtained to make progress. B, D, E cannot elect a leader without a quorum. A is quorum connected but cannot elect a new leader since it is still connected to the alive leader C.
Constrained Election:
When the leader loses quorum connectivity, deadlock situation as a majority cannot be obtained to make progress. B, D, E cannot elect a leader without a quorum. A is quorum connected but cannot elect a new leader since it is still connected to the alive leader C.
Constrained Election:
 Leader is fully disconnected. A can become the new leader but will not be elected as it does not have the most updated log (log length).
Leader is fully disconnected. A can become the new leader but will not be elected as it does not have the most updated log (log length).


# Failure recovery
- Recover state from persistent storage
- Send a
PrepareReqto all peers- If elected as leader, synchronise through a
Preparephase Preparephase from another leader will synchronise
- If elected as leader, synchronise through a
# Reconfiguration
Supporting a way to add/replace any process part of the replicated state machine. A configuration $c_i$ is defined by a set of process ids ${p1, p2, p3}$ and the new configuration can be any new set of processes e.g. ${p1,p2,p4}$
# Stop Sign
To safely stop the current configuration, we must prevent new decisions in the old configuration (“split-brain” problem) using a stop sign:
 The stop sign contains information about the new configuration to help processes reconfigure:
The stop sign contains information about the new configuration to help processes reconfigure:
- the new set of processes in $c_{i+1}$
- the new configuration id number
- the identifiers for each replica in the new configuration Each process on viewing the stop sign, can safely shut down and restart in the new configuration A new process not previously part of $c_i$ must perform log migration to catch up with the new instance. Log migration can be done with snapshots of the latest state.
# Raft
A state of the art consensus algorithm.
# State of servers
Rather than using process ids to break ties for leader election in omnipaxos, Raft uses a form of random retrying when there are split votes.

# Log Reconciliation
A server must have the most up to date log in order to become a leader, compared to omni-paxos where any server can be the leader and be synced up during the Prepare phase.
